Now, what we have discussed in the previous post is a very advanced technique of linear regression. So, essentially what i was saying is, we are adjusting weights and biases. We are creating a function, where we give a input and we are gonna get the output.
All we are doing for this just adjusting the linear function because our degree is only 1, weights of degree 1, multiplied by value of degree of 1 and we are adding some kind of biases (i.e v1w2 + v2w2 + v3w3 + v4w4 + v5w5 + b1 + b2 + b3 +b4 + b5). That gonna remind you the form mx + c (i.e y = mx + c)
We are literally adding a bunch of mx+c together which gives us a fairly complex linear function. But this is no really a great way to do things. Because it limits the degree of complexity that our network can actually have to be linear.
What activation function is, essentially a non-linear function that will allow you to add a degree of complexity to our network.
Sigmoid Function:
 |
| Image Source - Google | Image by - ResearchGate |
Some examples of an activation function is something like a sigmoid function. Now, sigmoid function what it does is, it will map any value given in between -1 and 1(in this case).
For example, when we create a neural network. The output might me like the number 7. The number 7 is close to closer to 1 than to 0 and -1, then it will map the output to 1 or it can say it a way off as it is above 7.
So, what we want in a output layer is that we want out output value to be in a certain range. In this case between 0 and 1 or we want them to be in between -1 and 1.
What the sigmoid activation function does is, it's a non-linear function and it takes any value and essentially the closet the value to +∞, close to the output 1 and any value close to -∞, closer to the output -1.
What it does is, it adds a degree of complexity to our network. The degree complexity is honestly how complex our network can it.
If we have a degree of 9, then the things gonna be much more complex. If we have only a linear function, then it gonna limit the degree of complexity by a significant amount.
What this activation also do is, they shrink down the data that is not as large. What we are gonna do is we have the equation ⅀(vi*wi + bi) we are gonna apply activation function to this, let f[x] be the activaiton funciton then f[⅀(vi*wi + bi)] and this is gonna give some value and that gonna be our output.
Why we are doing this is to, add a way more complex to our network. As supposed to be having a linear function.
Rectifier linear unit:-
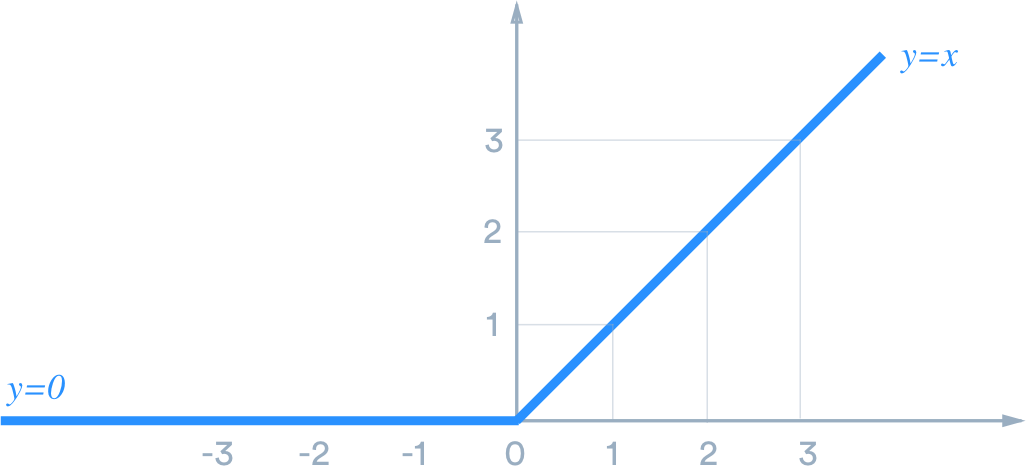 |
| Image Source - Google | Image by - Medium |
And what this does is, it takes all the values that are negative and automatically puts them to 0 and takes all the positive vales and just makes them more positive. It is a non-linear function, which is gonna enhance the complexity of our model and makes the data points in between the range 0 and +∞, which is better than having in between -∞ and +∞.
Post a Comment
Post a Comment